
【”Autify OCR”と”Google OCR”を比べてみた】AutifyのOCRを支えるMLUI Mobileについて

AutifyはWebアプリケーション向けのAutify for Webのほかに、モバイルネイティブアプリケーション向けのAutify for Mobileを提供しています。
Autify for Mobileには、MLUI-Mobileと呼ばれるMLベースのUI検出エンジンの上に構築された複数のMLベースの機能があります。
このエンジンには、社内で開発したOCRシステムを組み込んでいます。
現在、このエンジンはAutify for Mobileで提供している機能でのみ使われていますが、Autify for Webで提供している機能の一部と組み込めるよう、開発を進めています。
現状ユースケースは比較的限定されており(スクリーンショットにレンダリングされたテキストなど)、それらのユースケースでは私たちのOCRシステムは他の代替製品よりも優れていると言えます。
このブログポストでは、私たちのOCRをEasyOCRのようなオープンソースの代替製品や、Google Cloud OCRのようなクローズドソースのソリューションと比較したいと思います。
比較方法
私たちのユースケースの特殊性を考慮し、内部データセットの一部のみをテストしました。
そのため、他のデータセットでは結果が異なる可能性があります。
また、すべてのOCRエンジンにテキストのトリミング画像を与え、当社独自の検出器を使用したため、それぞれのエンジン独自の検出器を使用した場合、結果が偏る可能性があります。
使用したデータセット
私たちはテキストのバウンディングボックスを含む数千のアノテーションされたスクリーンショットを所持していますが、このデータセットにはテキストアノテーションが含まれていません。
これらのスクリーンショットからすべてのテキストボックスを切り取ります。このデータセットをシャッフルし、OpenAI CLIPを使ってサンプルの重複を排除し、1万個程度のサンプルだけを取り出します。
これらのボックスにはラベルがないので、Autify OCRとGoogle OCRの出力を比較し、出力が類似していれば、正しいものと見なします。
両方のエンジンが間違っている可能性もわずかにありますが、それは無視できるレベルです。
比較結果
当初私たちは、「3つのOCRエンジンからの結果が全て一致したらそれを正解と見なす」ことを考えていましたが、サンプルの約29%がこれに該当していました。
しかし、結果を見直したところ、Easy OCRが多くの誤りを犯していることに気づきました。
残りのサンプルについて、Easy OCRはAutify OCRと約3%、Google OCRと5%で一致していましたが、Google OCRとAutify OCRはサンプルの約45%で一致していました。
したがって、正解の推定データからEasy OCRの一致を取り除き、Google OCRとAutify OCRのみに依拠することとしました。
このとき、2つのエンジンの両方でサンプルの約70%が完全に一致しました。
次に、残りの30%からランダムに約150のサンプルを取り、社内でアノテーションを行ないました。
そのサンプルにおいて、Autify OCRは70%の確率で正確であるのに対して、Google OCRは30%でした。
これにより、Autify OCRの最終的な精度推定は約91%、Google OCRは約79%の精度であるという結果となりました。
結果に対する分析 ✨
私たちはこの結果を分析し、この数字の背後にあるいくつかの理由を調査し、論理付けしました。
Autify OCRの強みの一つは、日本語と英語の混在したコンテンツの処理であることがわかりました。
Google OCR は英語だけのケースや日本語だけのケースをうまく処理しており、Autify OCR よりも優れている場合もありました。
Autify OCR が非常に優れたパフォーマンスを示したもう一つの理由は、データドメインがスクリーンショットとレンダリングされたテキストのみに限定されていることです。
合成データセットでモデルをトレーニングする際に、非常に強力な拡張スキームを使用しました。
Google OCRとEasy OCRがうまく動作しない理由の1つは、テキストボックスのクロップが原因である可能性があります。
私たちはそれぞれのエンジンに、独自の検出器を使用する代わりに、事前に注釈を付けたクロッピングを与えました。
Easy OCRに特化したもう1つの理由は、彼らの事前学習されたモデルは実世界のテキストに最適化されており、学習データにレンダリングされたテキストがないことや、データドメインの広さが、特定のドメインで精度が低い原因である可能性があることです。
比較の実例

| Autify OCR | 配達料約¥2,000 |
|---|---|
| Google OCR | 配達料約¥2,000 |
| Easy OCR | 配達料約半2,000 |
Autify OCRとGoogle OCRはこのテキストを正しく予測しましたが、Easy OCRは「円」の記号を正しく認識しませんでした。
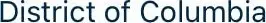
| Autify OCR | District of Columbia |
|---|---|
| Google OCR | District of Columbia |
| Easy OCR | District ot Columbia |
Easy OCRでは’of’が’ot’に分類されます。おそらく、非常にタイトなトリミングのためでしょう。
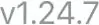
| Autify OCR | v1.24.7 |
|---|---|
| Google OCR | v1.24.7 |
| Easy OCR | V124.7 |
この例では、Easy OCRはバージョン番号のドット「.」を見逃しています。

| Autify OCR | 800-5000万 |
|---|---|
| Google OCR | 800-50005 |
| Easy OCR | 809-59gg万 |
ここではGoogle OCRも誤った判断をしています。そして Easy OCR は数字を正しく認識しませんでした。

| Autify OCR | you on The Pattern: |
|---|---|
| Google OCR | you on The Pattern. |
| Easy OCR | youonThe Pattern |
Autify OCRのミスは「.」「:」と混同したことです。これはデータ生成に起因する系統的なエラーで、私たちは最近この事象を特定し、修正に取り組んでいます。

| Autify OCR | RVs |
|---|---|
| Google OCR | RVS |
| Easy OCR | RVs |
ここではGoogle OCRは最後の’s’を大文字にしています。

| Autify OCR | 한국어 |
|---|---|
| Google OCR | 한국어 |
| Easy OCR | 計3叶 |
‘en’と’ja’しか言語を扱えなかったので、Easy OCRはテキストを日本語の文字に照らし合わせようとしました。
まとめ
MLUIの初期バージョンでは、しばらくEasy OCRを使用していました。
しかし、エラーの多さを考慮し、別のソリューションに移行することにしました。
Google OCRも検討しましたが、ミスが発生したときに改善できないという欠点がありました。
そこで私たちは、膨大な合成データセットと、速度と精度のトレードオフのために最適化されたアーキテクチャで訓練されたエンコーダ・デコーダ変換器である、非常に最適化された社内ソリューションを構築することにしました。
Autifyではこの他にも品質保証やテスト、アジャイル開発に役立つ資料を無料で公開していますので、ぜひこちらからご覧ください。

