
翻訳: Autifyにおけるモダンディープラーニングの活用

当記事は、弊社のシニアMLエンジニアによる “Applying modern deep learning in Autify” の日本語訳です。
ディープラーニングは、現代のAIの最前線を行くものです。かつてのソフトウェアエンジニアリング技術では不可能だと考えられていたアプリケーションが、次々とディープラーニングによって実現されています。 世の中のほぼあらゆるプロダクトがこの分野の技術によって支えられており、Autifyも例外ではありません。私たちは、ディープラーニングをプロダクトのさまざまな側面で活用しています。その進行状況をお伝えすべく、ディープラーニングによって支えられた今後発表予定のユースケースをご紹介しましょう。
ビジュアルテストのエンジン
ビジュアルテストのエンジンは、同じウェブサイトの複数のバージョンのスクリーンショットを視覚的に比較するテストを行えるようにするモジュールです。Adobe FREDにインスパイアされた私たちは、スクリーンショットの見た目に基づいて異なる領域を分類し、意味のある細分化を行うモデルを実装しました。ここでの目標は、ページ内に含まれるコンポーネントを抽出して複数のバージョンで比較できるよう、ウェブサイトのスクリーンショットにおいて有意義な表現を持てるようにすることです。このモジュールは、今後発表される予定のビジュアルテストのプラットフォームに統合される予定で、ユーザーの皆様はウェブアプリケーションを視覚的にテストできるようになるでしょう。
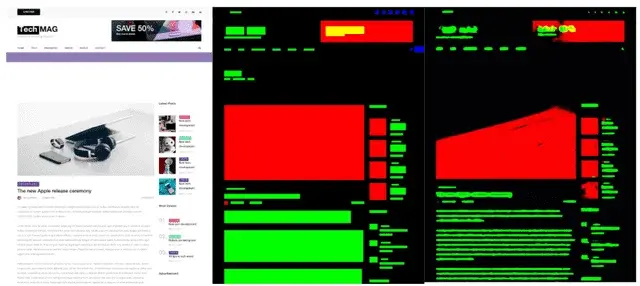
Feature Locatorの改善
Feature Locatorジェネレーターは、私たちのプロダクトの主要コンポーネントの一つで、複数のバージョンのウェブアプリケーションに渡り、レコーディングされたテストのセルフヒーリングを行います。 セルフヒーリングで利用されている手法の一つは、要素の異なる特徴に対して異なる重み付けを適用することです。当初このエンジンでは人手による特徴の重みづけが行われており、かなり上手く機能していたものの、ときどき問題が発生するケースもありました。
私たちはNode.jsのアプリケーション全体を最適化しているので、機械学習で用いられる勾配ベースの手法は利用できません。そこで、遺伝的アルゴリズムを使って動的にこれらのパラメータをチューニングし、人間が重み付けをするよりも多くの問題を解決できるようにしました。 今後のイテレーションにおいては、さらなる改善版をお披露目することになるでしょう。
Deep HTMLによる表現
HTMLは表現力のあるとても強力な言語で、Web全体の根幹を成すものです。しかしながら、HTMLはディープラーニングのコンテキストでは少々取り扱いづらいのも事実です。こんなときはグラフのニューラルネットワークが役に立ちます!
私たちはHTMLのノードの配置を計算するために、Seleniumから算出可能な動的な情報(locationなど)を含んだ、数値で表現可能なカテゴリ別の特徴や、HTMLの属性のような静的な情報を抽出しました。
このような情報を用いて、社内で準備したメジャーなウェブサイトのデータセットに対し、他の特徴からHTMLタグを45%に至る検証精度で分類することに成功しました。この結果を、以前は構造に関する情報が不足していたためにパフォーマンスが振るわなかった、従来の線形モデルと比較しました。(HTMLではクラスが非常に不均等に分布していることを念頭に置いてください。たとえば膨大な数のdiv要素があるので、バランスの取れた結果が得られるよう分類の重み付けを利用した形です)。
また、MLflowやOptunaのようなモダンなツールを利用して、実験の追跡やハイパーパラメータの最適化、すなわち活性化関数やニューラルネットワークの層数、およびキャパシティの選択を行いました。これにより、より少ない計算量でより良いモデルを見つけられるようになったのです。
インテリジェントなテストの発見
Autifyの主要機能は、ユーザーがウェブアプリケーションに対するテストをレコーディングして運用することです。しかし、テストケースをレコーディングするプロセス自体を自動化できたらどうでしょうか? そうです。現代的な強化学習を取り入れれば、ウェブアプリケーションのテストシナリオを自動生成することだってできるのです。これは、今後のAutifyの機能で最も便利なものの一つとなるでしょう。
おわりに
この記事では、将来が大いに期待できるAutifyでの研究をご紹介しました。きっと皆様も、私たちのプロダクトにワクワクしていただけることでしょう。 ご質問やお問い合わせは、私たちのアカウント@AutifyJapanまでお寄せください。今後のアップデートもお楽しみに!

